如何用R做文本挖掘
1、要分析文本内容,最常见的分析方法是提取文本中的词语,并统计频率。频率能反映词语在文本中的重要性,一般越重要的词语,在文本中出现的次数就会越多。词语提取后,还可以做成词云,让词语的频率属性可视化,更加直观清晰。比如下图:

2、这是根据总理2014年的政府工作报告制作的可视化词云,分词和词云的制作都是用R,词频的统计用了其他软件。这个图能很直观看到,工作报告的重心是"发展",这是大方向,围绕发展的关键要素有经济建设、改革、农村、城镇等要素。不过这张图中的词语还需要进行优化,因为有些术语或词组可能被拆分成了更小的词语,没有展示出来,为了演示,我就没再花更多时间去优化词库,主要是讲讲分析的方法。
下面是分析方法:
首先,要获得要分析的内容,做成txt文本文件。这个很简单,把要分析的内容粘贴到记事本,保存为txt文件就可以了。
其次,用R进行分词。这里要分几点来讲:
要用R进行分词,需要安装并装载两个library,一个是Rwordseg,另一个是rJava。rJava的作用是提供java的库,供Rwordseg调用。安装后,调用语句如下:
library(rJava)
library(Rwordseg)

3、说说Rwordseg,这是一个R环境下的中文分词工具,引用了Ansj包,Ansj是一个开源的java中文分词工具,基于中科院的ictclas中文分词算法,采用隐马尔科夫模型(HMM)。Rwordseg牛逼的地方三点,一是分词准确,二是分词速度超快,三是可以导入自定义词库,有意思的是还可以导入搜狗输入法的细胞词库(sqel格式),想想细胞词库有多庞大吧,这个真是太厉害了。
分词的语法。很简单,一个函数就搞定了,看下面:
segmentCN("待分析文件的完整路径",returnType="tm")
注意:R中的路径用"\\"分割文件夹。参数returnType表示返回的分词格式是按空格间隔的格式。执行完成后,会自动在相同目录生成一个"待分析文件名. .segment.txt"的文本文件,打开可以看到是酱紫:

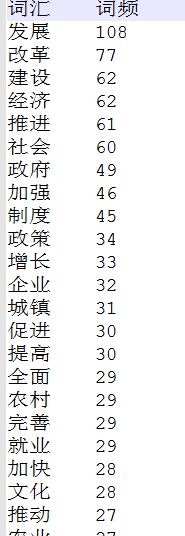
4、然后,要统计词频。到了这里,每个单词出现的频率是多少,需要统计出来。这个词频统计,我在R中找了一阵,没有找到合适的工具来统计,有人说lm可以统计,试了试不行。于是乎用了其他的软件。这方面的软件不少,大家可以找找,总之,统计出来是酱紫的:
5、最后,就是画成词云。R有工具可以画词云,当然互联网上有不少网站可以在线制作词云,做得也很漂亮,有兴趣可以去找找,我这里只谈R中的方法:
安装并装载画词云的工具包wordcloud:
library(wordcloud)
读取已经统计好词频的文件:
mydata<-read.table("已统计好词频的文本文件的完整路径",head=TRUE)
设置一个颜色系:
mycolors <- brewer.pal(8,"Dark2")
画图:
wordcloud(mydata$词汇,mydata$词频,random.order=FALSE,random.color=FALSE,colors=mycolors,family="myFont3")

6、最后的效果图
